



Join a community of professionals who push each other to strive for success, while enjoying what they do. We like to share knowledge and experiences and to inspire each other every day.
Years on the market
Employees
Nationalities







Join a community of professionals who push each other to strive for success, while enjoying what they do. We like to share knowledge and experiences and to inspire each other every day.
Years on the market
Employees
Nationalities

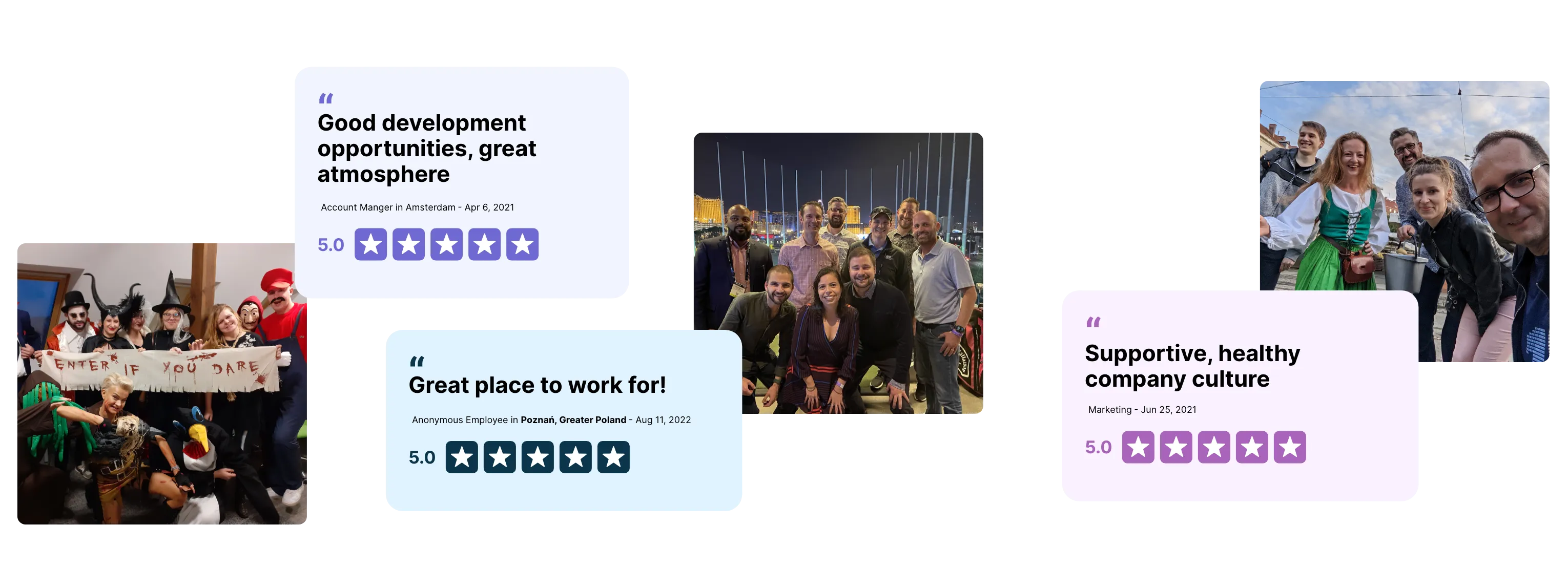


We keep the balance between performing well and being relaxed at the same time. Work hard. Play hard. Stay cool.


We don’t talk forever. We drive our ideas to the execution stage and make things happen.


Cleeng is a place where you can trust your colleagues, where you feel that others rely on you. We do what we say and we say what we do. To each other, and to our clients.


We believe in the importance of good communication and transparency. We work together, give feedback, and help each other.



We keep the balance between performing well and being relaxed at the same time. Work hard. Play hard. Stay cool.
We don’t talk forever. We drive our ideas to the execution stage and make things happen.
Cleeng is a place where you can trust your colleagues, where you feel that others rely on you. We do what we say and we say what we do. To each other, and to our clients.
We believe in the importance of good communication and transparency. We work together, give feedback, and help each other.
we offer to help you reach your best potential

Immerse yourself in a culture full of diversity. Travel the world to work face-to-face with your colleagues and enjoy the ride!

Within the viable limits you have a possibility to choose the type of pc/laptop you want to work on.

We work efficiently from any place: from home, office or fully remotely

We are thriving in a booming and exciting industry where you could develop your skills.

Successful projects, anniversaries, other special occasions. We love celebrating them with you!

We work hard to create a welcoming space in which we feel good - supported and safe




